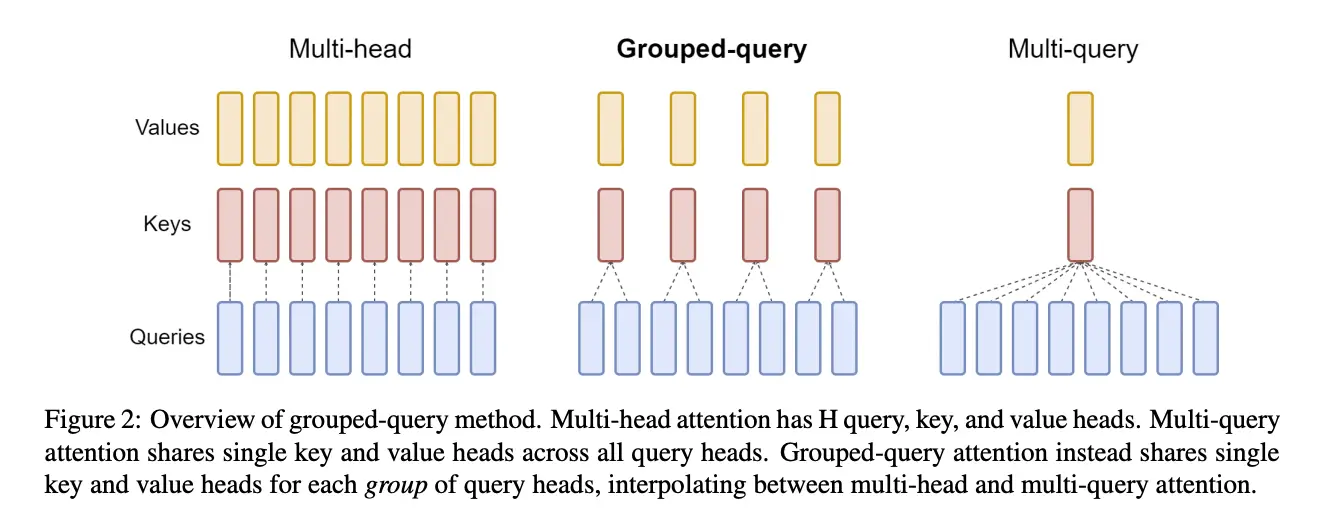
Grouped Query Attention (GQA) is an attention mechanism that combines elements of multi-head attention (MHA) and multi-query attention (MQA) to enhance efficiency and performance in large language models (LLMs).
In GQA, query heads are divided into groups, with each group sharing a single key head and value head.

This structure allows the model to achieve a balance between the quality of MHA and the computational efficiency of MQA.
GQA maintains the diversity of attention patterns seen in MHA while reducing the computational and memory overhead associated with processing multiple key and value heads, similar to MQA. This results in performance that is close to MHA but with speed and resource usage comparable to MQA (source).
For a practical implementation, you can refer to the PyTorch implementation which provides a detailed example of how GQA can be coded.